Problem
Design engineers currently get little to no feedback on life-cycle cost factors including manufacturing failures, obsolescence, or ergonomics/automation until manufacturing reviews are held late in design cycles.
Leveraging artificial intelligence and machine learning (AI/ML) cloud models developed with manufacturing data, CODA will help design engineers reduce engineering change orders (ECOs).
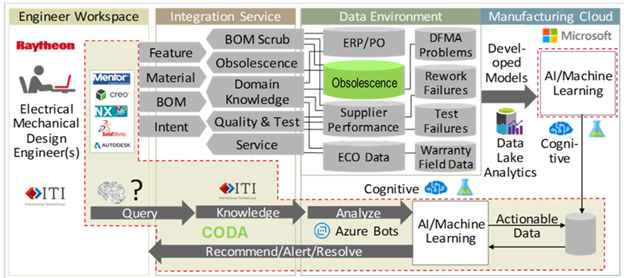
CODA provides the tool integration, platform, and process framework to leverage AI to generate obsolescence risk based on historical manufacturing data. The CODA framework, scripts, applications, and instructions are available to MxD members. The delivered scripts represent the demonstration environment.
CODA is broken down into 4 key components: engineering workspace, integration service, data environment, and AI/ML cloud development.
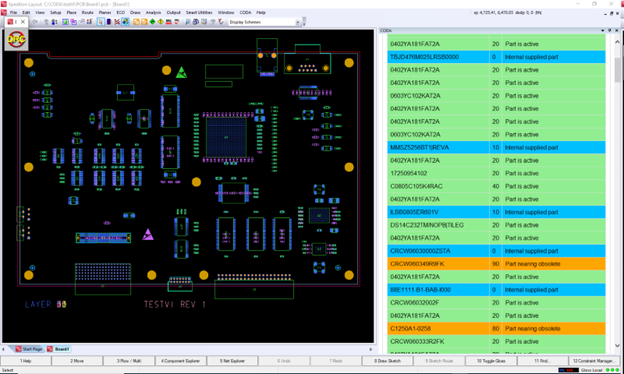
Engineering Workspace. This represents the tools available to design engineers; the optional frontend for the design to be analyzed. CODA is built to integrate with all the commonly used design tools with a direct connection or a link through the integration framework. CODA was demonstrated as an add-in to the Siemens Xpedition platform for circuit card design to show results in real-time within the platform; no manual effort to extract or correlate results.
Integration Service. ITI’s Linked Intelligent Master Model (LIMM) platform provided the communication and security infrastructure required to interface with the generated ML and recommendation framework. The LIMM API provides the framework to submit the required design information through LIMM, package the format for the ML endpoint, and retrieve the results. LIMM then stores this information for each analysis such that the users can access current and historical results.
Data Environment. The system architecture includes leveraging existing data information within the Raytheon ecosystem, their suppliers, and rules/analysis generated from subject matter experts.
AI/ML Cloud Development. Microsoft Azure Machine Learning Workspace environment and development tools were used to pull together key supplier and internal historical data to calculate obsolescence using a Random Forest and k-nearest neighbors (KNN) approach. The Project Team used a combination of physical hardware, virtual machines on-premise, cloud services and storage accounts, and hosted endpoints.